Abstract + Introduction
- First-stage ranker 的新架構 DenseTrans - Transformer + DenseNet 的融合物
- 主要的任務是question retrieval,找出與使用者輸入相似的問題,類似FAQ
Term-based的方式會有 無法滿足 Semantic Requirement 的缺點
Dense Vector embedding的方式則通常會因為段落中有Noise,可能無法滿足 Discriminative Requirement, 也就是說一般會沒有辦法很容易的判別出relevance的文章,容易造成誤判
通常做為First-stage ranker recall很重要,所以必須滿足以上兩個需求才能算是好的Model
為了滿足Discriminative Requirement ,作者任為必須加入較low-level的特徵來滿足,傳統的transformer可能因為太深了,都只能學到比較high-level的representation,因此透過Dense讓transformer在學習過程中持續接收low-level的資訊,也可有效過濾Noise
Method
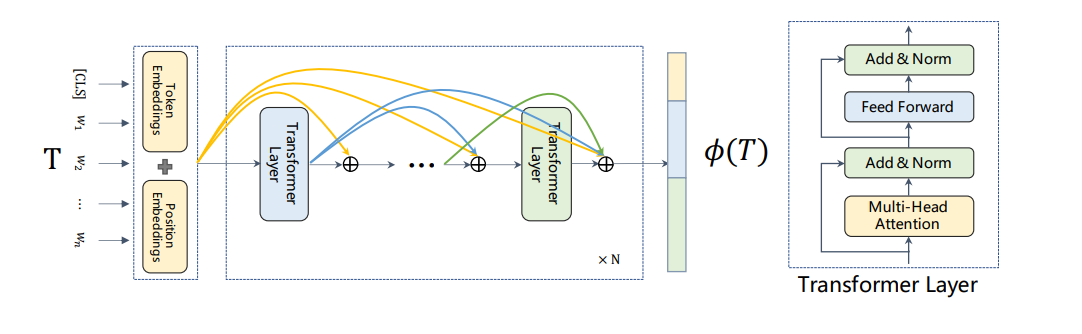
Model如上圖,就是將transformer裡面的每層output都傳給接下來的每一層,也就是
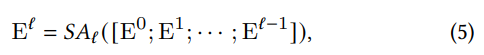
其中 $E^i$ 代表第i層的transformer輸出
比較特別的訓練技巧為
- we do not use the transition layers and the batch normalization since the DenseTrans only uses a few layers (𝑁 = 3)
然後訓練的過程主要跟一般的IR訓練相同為
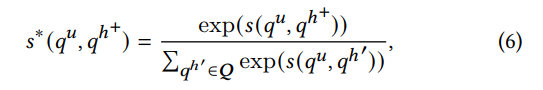
Experiments
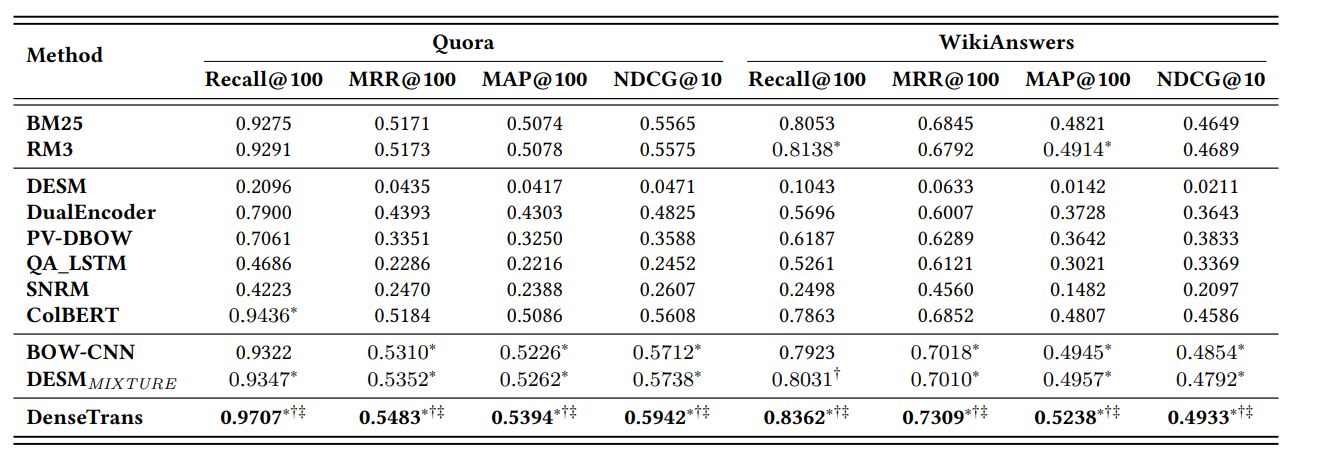
實驗結果

比較Dense 是否有效
上圖為了測試Dense連接是否有效分別做了
- -TopDense
- remove the dense connections from the last layer, and keep the dense connectivity between low layers.
- -AllDense
- remove all the dense connections from the DenseTrans model
- model only keep the highly abstract semantic information
- +Concat
- concatenating the outputs of all layers of the −AllDense
- detailed low-level features are really important for question retrieval
Conclusion
Introduce the dense connectivity between the Transformer layers to strengthen the discriminative power during semantic representations abstracting