簡介
這顆Model是朋友跟我說可以用用看,很多中文的比賽都用這個Model我才知道,因此簡單記錄一下
這個Model 主要有這些貢獻
- 進行了廣泛的廣播研究,通過詳細分析語言中文預訓練語言模型在各種任務上的表達。
- 改善傳統BERT欲訓練[MASK] token 不出現在下游任務,導致預訓練任務跟實際任務不符的缺點,macBERT是用同義詞來取代token
- 為了改善中文NLP,發布預訓練Model
Method
- 用 WWM (whole word masking) 跟 n-gram 來選要被替換的tokens
- uni-gram - 4-gram 的比例是 40%、30%、20%、10%。
- 原始BERT模型使用[MASK] token 進行mask,但是[MASK] token 在fine-tuning / downstream task不會出現,會造成預訓練任務與fintuning的不一致,因此用同義詞來替換token
- A similar word is obtained by using Synonyms toolkit (Wang and Hu, 2017), which is based on word2vec
- If an N-gram is selected to mask, we will find similar words individually. In rare cases, when there is no similar word, we will degrade to use random word replacement
- 15% input words for masking
- 80% will replace with similar words
- 10% replace with a random word
- keep with original words for the rest of 10%

- Comparisons of the pre-trained language models. (AE: Auto-Encoder, AR: Auto-Regressive, T: Token, S: Segment, P: Position, W: Word, E: Entity, Ph: Phrase, WWM: Whole Word Masking, NM: N-gram Masking, NSP: Next Sentence Prediction, SOP: Sentence Order Prediction, MLM: Masked LM, PLM: Permutation LM, Mac: MLM as correction)

Experiments
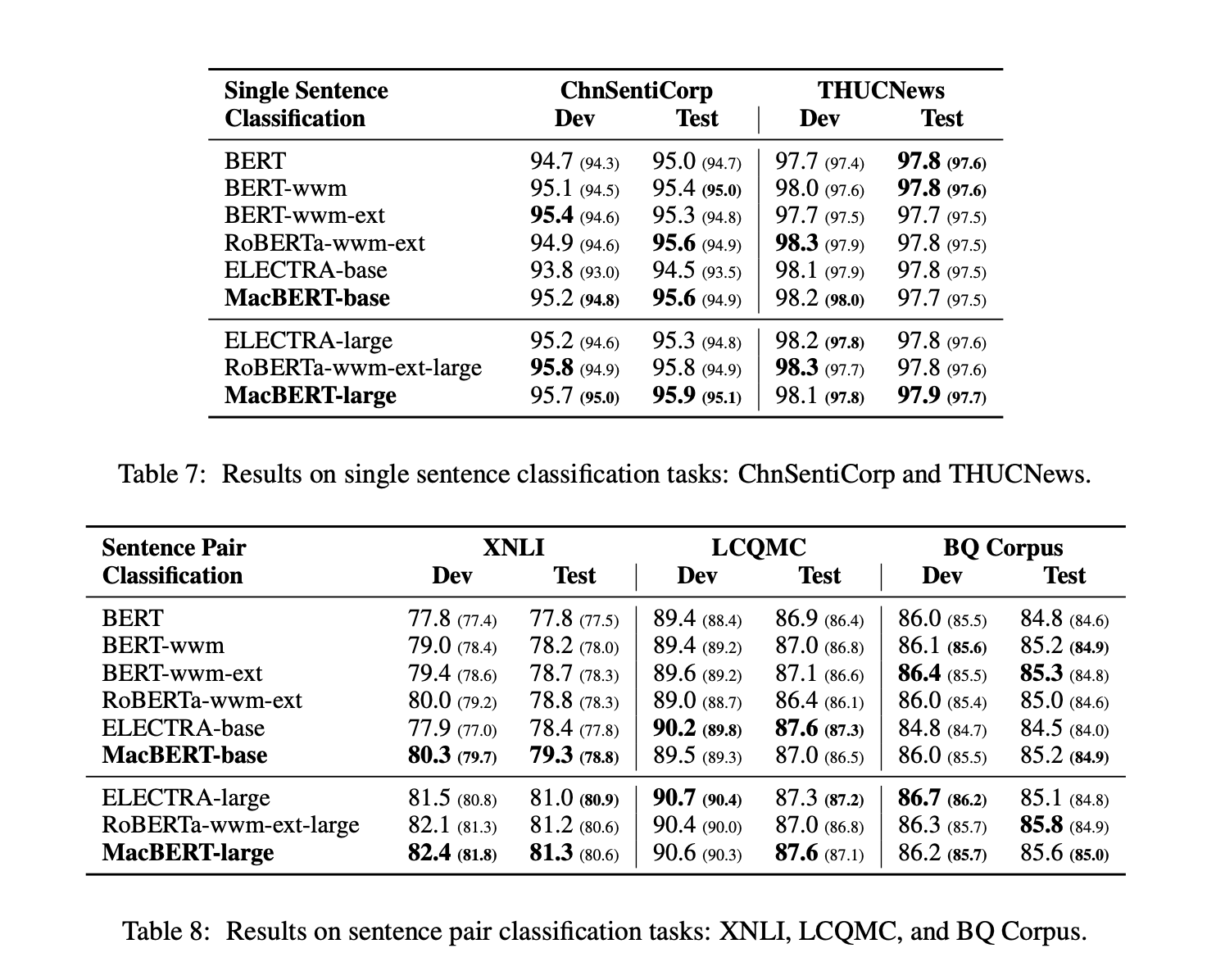
實驗結果看起來賊牛逼,老鐵666666
Conclusion
實測好用