Abstract + Introduction
- difficult to effectively train a dual-encoder for dense passage retrieval
- retriever needs to identify positive passages for each question from a large collection
- there might be a large number of unlabeled positives (IR資料集可能有錯誤)
- it is expensive to acquire large-scale training data for open-domain QA
反正就是large scale 的open-domain QA Model很難train,所以提出了三種方法來改善整個流程
- cross-batch negatives
- denoised hard negatives
- leverages large-scale unsupervised data “labeled” by a cross-encoder for data augmentation
Method
主要相似度公式是採用dot-product
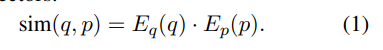
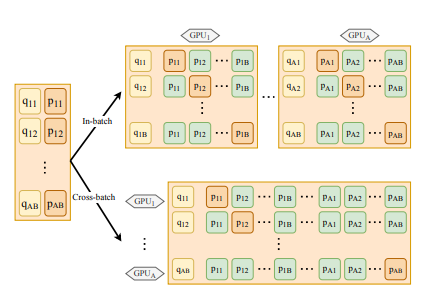
Cross-batch Negatives
- in-batch negatives has been widely used in previous work
- first compute the passage embeddings within each single GPU, and then share these passage embeddings among all the GPUs - 現在單個gpu算出embedding,再分享給其他gpu一起共用,negative的數量多了N倍 (N個GPU的話)
Denoised Hard Negatives
- Traditional method may bring false negatives (unlabeled positives)
- find that about 70% of them are actually positives or highly relevant in 100 questions
- 大型的IR資料集會有漏標positive的問題
- utilize a well-trained cross-encoder to remove top-retrieved passages that are likely to be false negatives
- Cross-encoder architecture is more powerful for capturing semantic similarity via deep interaction
Cross-Encoder判斷出來可能要低於一定的值(<0.1)才真正當作negative,透過Cross-Encoder挑出真正夠negative的來幫助Model學習
Data Augmentation
- utilize cross-encoder to annotate unlabeled questions for data augmentation
- only select the predicted positive and negative passages with high confidence scores estimated by the cross-encoder
也是用Cross-Encoder對unlabeled資料生成label,大於0.9=positive,小於0.1=negative
訓練流程
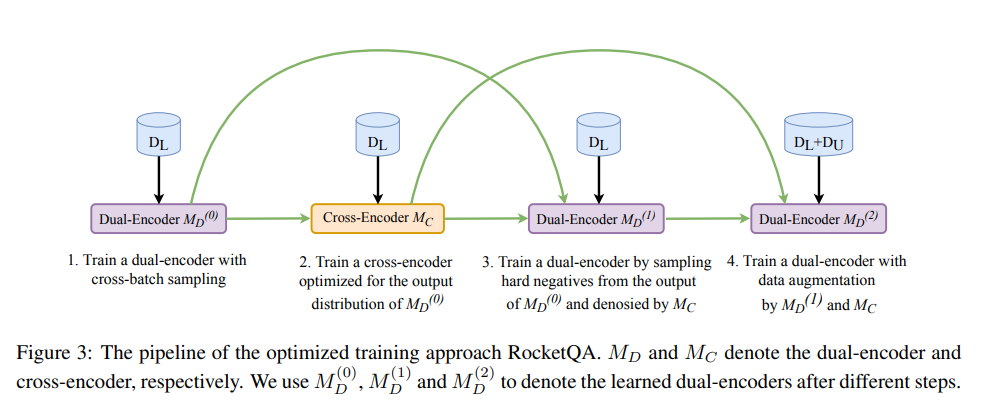
- 先用labeled 資料 Train 一個 dual-encoder (cross-batch) ,這邊的negative 就是random取或是取BM25 的topk也行
- Train一個Cross-encoder,training 資料中的positive 是原本data中的positive,negative是利用前一步的dual encoder猜出來的top-k passage並且不屬於positive passage,來當作negative (hard negative by Md)
- train 另一個 dual-encoder ,用上一步的資料做 label denoised ,除了 hard negative by Md之外且cross-encoder (MC) 也要猜是negative 才算是真正的negative(Denoised)
- pseudo label data MD1 先抽 topk 再用 Mc 標label最後在train一個MD2 Dual encoder 負責retrieve top k 個passage , cross encoder 負責denoised 跟生成unlabel data
Experiments
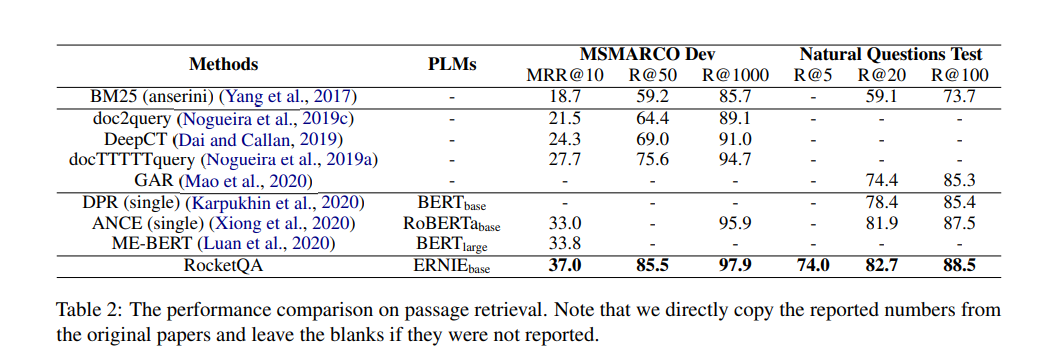
實驗結果
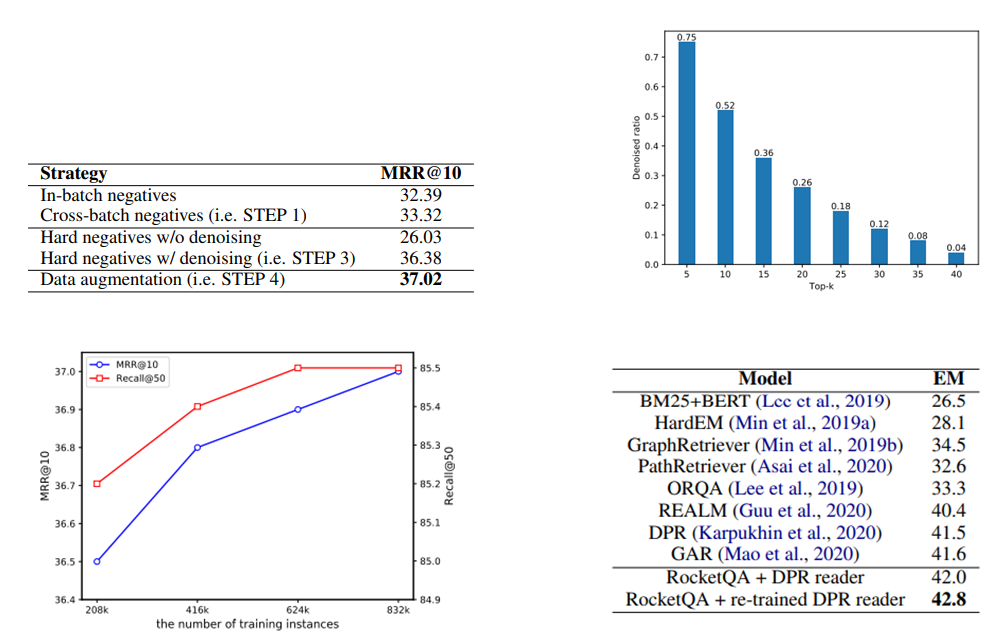
- 左上
- 這邊是在比較每一步驟中Model的表現結果,可以看到Denoised過後差了10!
- 右上
- 這邊再講說Dual-Encoder取出來的topk中,需要被Denoised的比例,可以看到真的滿高的
- 左下
- 經過Data Augmentation之後生越多資料Model表現越好
- 右下
- 這邊是串後面的QA架構之後的整體表現
Conclusion
這篇看下來我覺得最有用的是Denoised的部分,也是整體表現提升的關鍵點